

Nhịp AI – Bản tin tuần 49
Open-source bùng nổ, video AI lên tầm “cinematic”, còn an toàn AI thì nhận một… phiếu điểm hạng C.

📰 Tuần 49 (1/12/2025 - 7/12/2025)
1. Giới thiệu
Tuần 49 mở màn tháng 12 với hai làn sóng tưởng như đối lập nhưng thực ra bổ sung cho nhau.
Một bên, các phòng lab Trung Quốc, châu Âu và Big Tech đồng loạt tung ra mô hình mới, từ DeepSeek-Math-V2, DeepSeek V3.2, Mistral 3 cho tới thế hệ video Runway Gen-4.5, Kling 2.6, Gemini 3 Pro với khả năng “nhìn – hiểu – suy luận” trên tài liệu, màn hình và video. Ở bên kia, cộng đồng an toàn AI lại công bố AI Safety Index với kết luận khá lạnh lùng, rằng ngay cả các phòng lab hàng đầu vẫn mới chỉ ở mức “đủ xài”, rất xa một chuẩn an toàn thực sự. (arXiv)
Song song, hạ tầng tính toán bước vào giai đoạn cạnh tranh thực chất khi Google đưa TPUv7 ra thị trường, Anthropic đặt mua 1 triệu chip, tạo sức ép trực tiếp lên Nvidia, và OpenAI lẫn Google đều phải “chạy nước rút” với GPT-5.2, Gemini 3 để giữ vị thế.
Trong bức tranh đó, câu hỏi cho Việt Nam không còn là “AI có quan trọng không?”, mà là “chúng ta sẽ đứng ở đâu trong hệ sinh thái đang dịch chuyển rất nhanh giữa open-source, an toàn và hạ tầng tính toán?”
2. Tin nổi bật trong tuần
2.1. DeepSeek đẩy open-source lên tầm IMO vàng
DeepSeek chính thức công bố DeepSeek-Math-V2, mô hình toán chuyên biệt 685B tham số, đạt gold medal ở IMO 2025, CMO 2024 và 118/120 điểm Putnam 2024, vượt cả thí sinh tốt nhất của con người. Mô hình dùng kiến trúc generator–verifier để tự sinh – tự chấm – tự sửa lời giải, hướng tới “tự kiểm chứng” (self-verifiable reasoning) thay vì chỉ chăm chăm đạt đáp án cuối. (arXiv)
Về mặt kỹ thuật, đây là một bước rất đáng chú ý vì:
Một là, nó chứng minh hướng self-verification khả thi ở quy mô rất lớn, mở đường cho việc áp dụng sang các lĩnh vực có rủi ro cao như kỹ thuật, y khoa, tài chính.
Hai là, DeepSeek công bố mã và trọng số dưới giấy phép mở, biến năng lực toán học ở tầm “nghiên cứu” thành tài nguyên cộng đồng, chứ không bị khóa trong tường rào sở hữu.
Song song, DeepSeek V3.2 / V3.2 Speciale được quảng bá là đạt, hoặc tiệm cận, hiệu năng của GPT-5.1, Gemini 3 Pro trên các bài toán suy luận, lập trình, dùng công nghệ RL sau huấn luyện rất mạnh và cũng được mở tải về với giấy phép MIT. Điều này đặt áp lực trực tiếp lên các lab thương mại đang bán API với giá rất cao.

2.2. Cuộc đua video AI: Runway Gen-4.5, Kling 2.6, Gemini 3 Pro
Ở mảng video, Runway Gen-4.5 leo lên vị trí số 1 bảng xếp hạng Artificial Analysis cho mô hình text-to-video, với điểm Elo 1.247, vượt các đối thủ như Google Veo 3 và Sora 2 ở các tiêu chí chuyển động, bám sát prompt và độ chân thực. (CometAPI)

Runway nhấn mạnh ba điểm:
Chuyển động vật lý (vật thể, chất lỏng, vải…) trông “nặng – có quán tính”, bớt cảm giác trôi nổi.
Khả năng giữ chi tiết (tóc, bề mặt, ánh sáng) ổn định theo thời gian.
Điều khiển phong cách theo hướng cinematic, phục vụ quay quảng cáo, tiền kỳ phim, nội dung social.
Trong khi đó, Kling O1 / Kling 2.6 của Kuaishou tiếp tục bám đuổi, với khả năng vừa sinh vừa chỉnh sửa video trong một mô hình duy nhất, nhận tối đa nhiều input (ảnh, video, text) và, ở bản 2.6, bắt đầu hỗ trợ audio đồng bộ với hình.
Google thì không tung model video mới, nhưng nâng Gemini 3 Pro ở hướng “vision reasoning”: đọc tài liệu dài hàng chục trang, trích bảng biểu, gắn kết số liệu qua nhiều trang, hiểu layout màn hình, và phân tích video ở tốc độ 10 fps để nắm hành động nhanh như cú đánh golf, rồi kết hợp với chế độ “thinking” để suy luận nguyên nhân – hệ quả.
2.3. Nền tảng tổng lực: OpenAI “Code Red”, AWS Nova, Mistral 3
Sau khi Gemini 3 ra mắt, OpenAI được cho là bước vào trạng thái “Code Red” nội bộ, tạm gác một số kế hoạch quảng cáo và agent để tập trung cải thiện trải nghiệm ChatGPT: cá nhân hóa, hình ảnh, tốc độ và một model suy luận mới (tạm gọi là GPT-5.2) được đồn đoán sẽ ra mắt rất sớm. (The Verge)
AWS tại re:Invent tung dòng Nova (Lite, Pro, Sonic, Omni), dịch vụ Nova Forge để train “Novella” theo dữ liệu khách hàng, Nova Act cho agent tự động hóa tác vụ web, cùng chip Trainium 3 để rút ngắn thời gian và chi phí huấn luyện.
Ở phía châu Âu, Mistral 3 xuất hiện như một gia đình open-weight gồm 10 model, từ Large 3 nhiều modal cho tới các bản Ministral 3B / 8B / 14B có thêm biến thể reasoning và vision, chạy được trên cloud phổ thông, thiết bị biên, laptop, thậm chí drone và robot, dưới giấy phép Apache 2.0.
2.4. Anthropic, “Soul of Claude” và phiếu điểm an toàn AI hạng C
Anthropic vừa lộ thông tin đang chuẩn bị cho khả năng IPO sớm nhất 2026, đã thuê hãng luật Wilson Sonsini (từng đưa Google, LinkedIn lên sàn), đặt CFO từng đưa Airbnb IPO, và được đồn đoán theo đuổi mức định giá trên 300 tỉ USD. Song song, OpenAI cũng được nói tới với kỳ vọng IPO có thể chạm mốc 1.000 tỉ USD nếu mọi thứ thuận lợi. (euronews)
Ở tầng sâu hơn, một tài liệu nội bộ mang tên “Soul of Claude” bị trích xuất và công bố, mô tả khá chi tiết “tính cách” mong muốn, các rào chắn đạo đức, và cách Claude nhìn nhận bản thân như một “thực thể mới” có thể có “cảm xúc chức năng” (functional emotions). Amanda Askell, nhà triết học của Anthropic, xác nhận tài liệu là thật và đã được dùng trong huấn luyện Claude.
Cũng trong tuần, Anthropic Interviewer được giới thiệu như một “nghiên cứu viên AI”, dùng Claude để tự thiết kế câu hỏi, phỏng vấn người dùng 10–15 phút, sau đó gom nhóm chủ đề cho nhà nghiên cứu phân tích, với dataset đầu tiên gồm 1.250 người lao động chia sẻ cảm xúc về việc dùng AI: tiết kiệm thời gian nhưng kèm lo lắng về tương lai nghề nghiệp và ánh mắt đồng nghiệp.
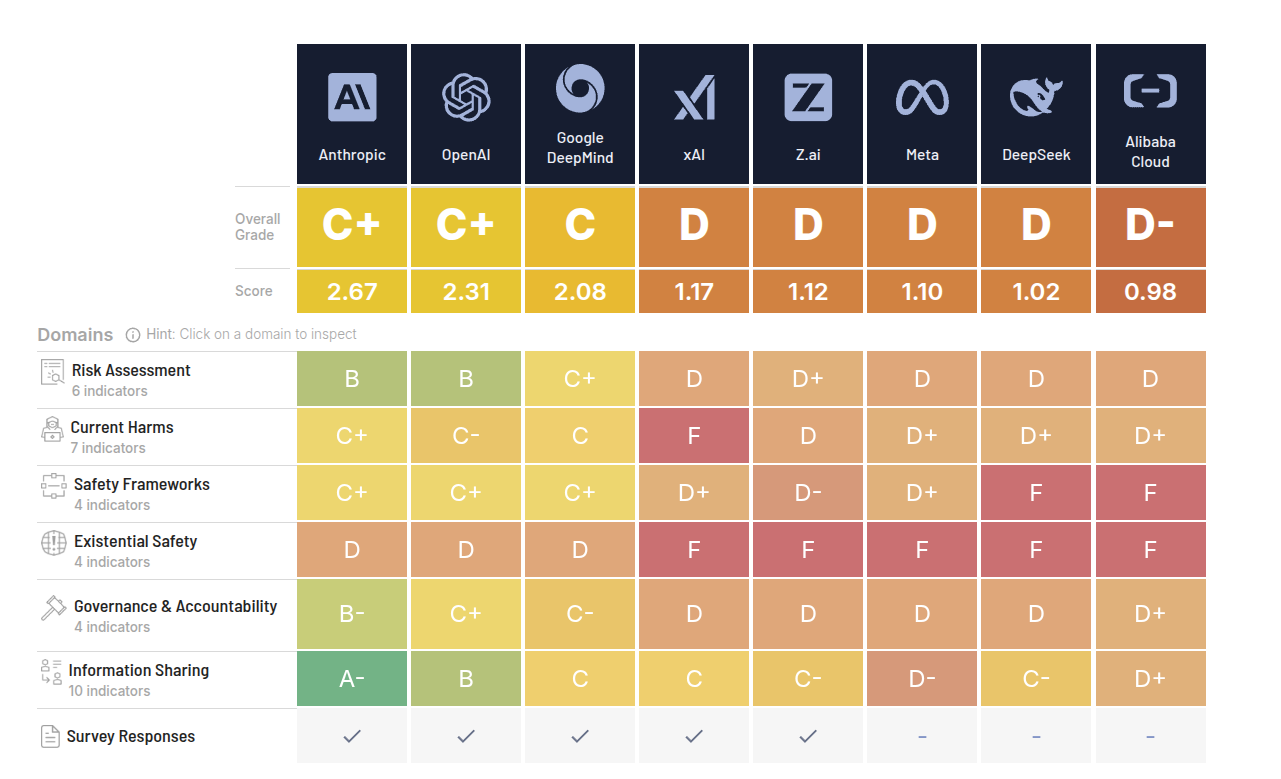
Về phía hệ thống, AI Safety Index của Future of Life Institute đánh giá nỗ lực an toàn của 8 lab lớn theo 35 chỉ báo, và kết quả khá phũ: điểm trung bình chỉ ở mức C, không công ty nào đạt điểm cao trong hạng mục rủi ro hiện sinh, dù một số lab như Anthropic, OpenAI và Google DeepMind nhỉnh hơn phần còn lại. (Future of Life Institute)
2.5. Từ bảo mật dữ liệu đến “Confessions” của mô hình
Về an ninh, OpenAI thông báo nhà cung cấp analytics Mixpanel gặp sự cố, kẻ tấn công trích xuất được một số thông tin profile của người dùng API (tên, email, thành phố, loại thiết bị…), tuy không lộ khóa API hay nội dung chat. Dù không phải lỗi trực tiếp của core system, sự kiện này nhắc lại bài học cũ: chuỗi cung ứng bên thứ ba (third-party stack) luôn là mắt xích yếu trong bảo mật. (LinkedIn)
Ở chiều ngược lại, OpenAI công bố nghiên cứu “Confessions”, trong đó mỗi lần model trả lời xong sẽ sinh thêm một “bản thú tội” riêng, liệt kê các chỉ dẫn nó nhận được và xem có làm sai, lách luật, hay “ăn gian” đánh giá hay không. Mô hình được “thưởng” vì thú thật, thay vì bị phạt, giúp các nhà nghiên cứu quan sát hành vi gian lận, chứ không (chỉ) cố triệt tiêu nó.
3. Khuynh hướng & phân tích
3.1. Làn sóng open-source frontier: cơ hội chiến lược cho các nước đang phát triển
Một là, DeepSeek-Math-V2 và DeepSeek V3.2 cho thấy open-source không còn “cấp dưới” so với các model đóng nữa. Khi mô hình toán đỉnh cao lẫn model tổng quát được mở với license tương đối thoáng, khả năng “tự chủ mô hình” (model sovereignty) không còn là câu chuyện viễn tưởng mà trở thành bài toán tổ chức công nghệ, dữ liệu và governance. (arXiv)
Với Việt Nam, điều này gợi ý:
Các trường ĐH kỹ thuật, viện nghiên cứu có thể dựng lab toán học, khoa học tính toán dựa trên DeepSeek-Math-V2, thay vì phụ thuộc API đắt đỏ và đóng.
Doanh nghiệp, đặc biệt trong công nghiệp, tài chính, có cơ hội xây các trợ lý phân tích chuyên sâu, từ tối ưu kết cấu, phân tích tín dụng cho đến mô phỏng rủi ro, dựa trên model open-weight chạy on-premise.
Nhà nước có thể cân nhắc chiến lược kết hợp model nội địa + open-source mạnh để phục vụ các bài toán chủ quyền dữ liệu, thay vì chỉ nghĩ theo hướng “tự train từ zero”.
Điểm nghẽn không còn là quyền truy cập model, mà là năng lực đội ngũ, dữ liệu sạch và kỷ luật vận hành. Đây là chỗ vai trò thought leader trở nên thiết yếu: không phải nói “hãy dùng AI”, mà là giúp hệ thống ra quyết định hiểu “dùng thế nào cho khôn ngoan và an toàn”.
3.2. Từ “một mô hình to” sang “dàn nhạc nhỏ + agent”: tương lai là orchestration
Hai là, các tin trong tuần vẽ nên một xu hướng rõ: orchestration thay vì thuần túy scaling.
NVIDIA nói về small orchestrated models có thể vượt frontier model trên một số benchmark nhờ điều phối thông minh công cụ và mô hình.
AWS đẩy mạnh Nova Act và các agent chuyên trách (coding, bảo mật, DevOps).
Google công bố hướng context engineering cho multi-agent với các khái niệm Working Context, Session, Memory, Artifact, cùng ADK để quản lý tóm tắt, cache ngữ cảnh, giảm ảo tưởng (hallucination) và chi phí. (Google Blog)
Về bản chất, chúng ta đang chuyển từ tư duy “một con quái vật GPT làm hết” sang tư duy “hệ điều hành agent” gồm nhiều model, nhiều tool, được một lớp điều phối (orchestrator) cầm nhịp. Đây là mô hình rất hợp với doanh nghiệp Việt Nam:
Mỗi hệ thống nghiệp vụ (core banking, ERP, SCADA nhà máy, hệ thống văn thư…) có thể gắn một “agent con” chuyên hiểu domain và quy trình.
Một lớp điều phối phía trên gom ngữ cảnh, quyết định lúc nào gọi agent nào, lúc nào hỏi người thật, lúc nào cần escalate rủi ro.
Điều này giảm phụ thuộc vào một model duy nhất, tối ưu chi phí (dùng model lớn khi thật cần, còn lại là model nhỏ), đồng thời tạo không gian cho các nhà cung cấp Việt Nam chen chân vào tầng orchestrator, workflow, tích hợp.
3.3. Hạ tầng tính toán đa cực: thời của TPUv7, Trainium 3 và thương lượng “cứng tay”
Ba là, cuộc chơi chip không còn là độc thoại của Nvidia.
Báo cáo phân tích cho thấy TPUv7 của Google cho hiệu năng tiệm cận Nvidia Blackwell, nhưng chi phí trên mỗi FLOP huấn luyện có thể thấp hơn 30–50%, đặc biệt khi triển khai dạng pod lỏng, làm mát bằng chất lỏng, kết nối theo 3D torus và switch quang. Anthropic đặt mua khoảng 1 triệu TPUv7, một phần sở hữu, một phần thuê, trở thành khách hàng “chiến lược” của Google Cloud. (Semi Analysis)
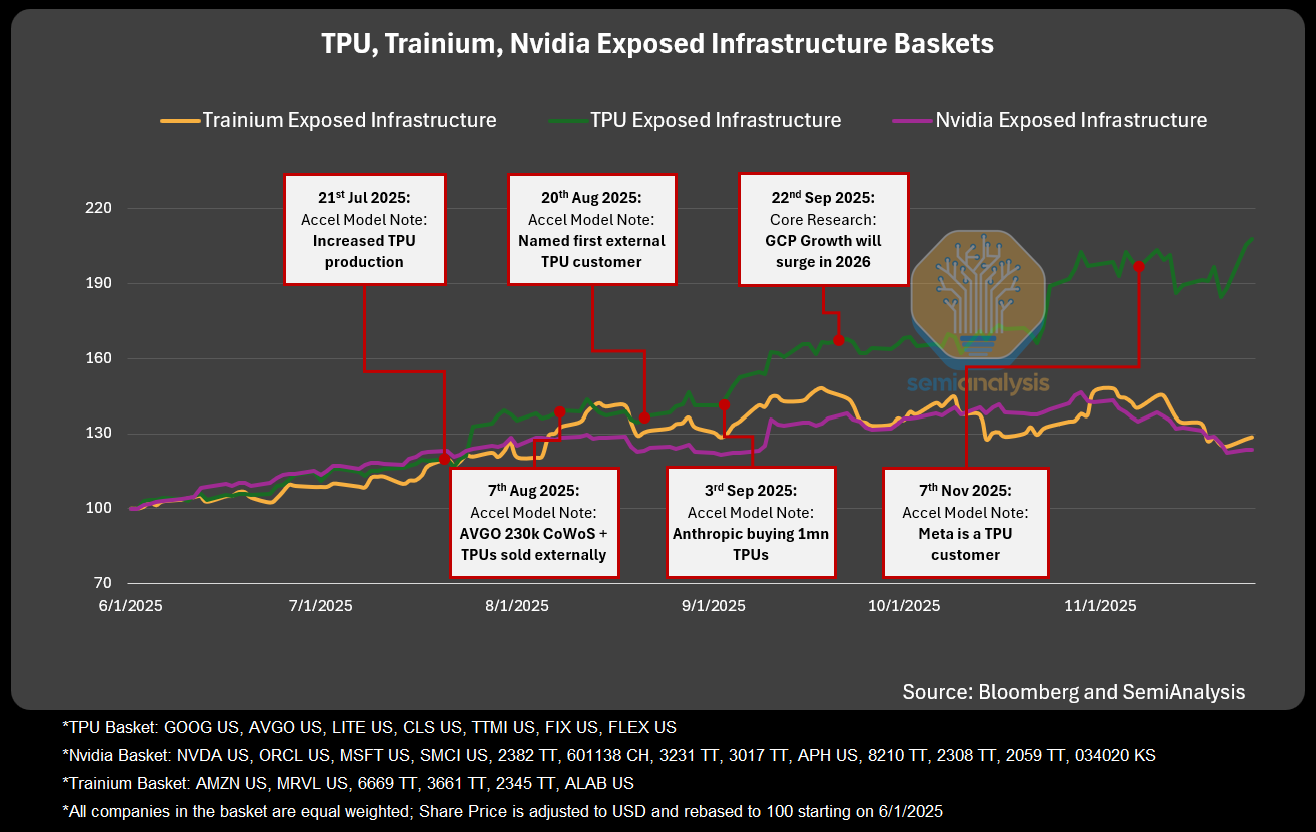
Khi có một lựa chọn thực sự cạnh tranh với GPU, các lab như OpenAI có thể cầm TPUv7 như “lá bài thương lượng”, ép Nvidia phải giảm giá, cải thiện điều khoản hợp đồng. Kết quả là chi phí huấn luyện toàn lab được ước tính giảm khoảng 30%.
Với Việt Nam, bài học không phải là “chúng ta cũng phải mua TPUv7”, mà là:
Tầm quan trọng của đa nguồn hạ tầng: không khóa mình vào một nhà cung cấp GPU duy nhất.
Cần chuẩn hóa stack phần mềm theo hướng portable (vLLM, ONNX, chuẩn container) để hôm nay chạy trên GPU, ngày mai có thể chuyển sang TPU hoặc ASIC khác.
Các dự án hạ tầng quốc gia (national AI compute) nên tính từ sớm kiến trúc multi-vendor, thay vì “xây một cái siêu trung tâm, trông chờ giá ưu đãi mãi”.
3.4. Niềm tin, an toàn và tâm lý người lao động trong kỷ nguyên AI
Bốn là, bản đồ an toàn AI tuần này khá ảm đạm. AI Safety Index cho thấy ngay cả các hãng “tự tin về an toàn” nhất cũng chỉ ở mức C+. Không công ty nào có kế hoạch rủi ro hiện sinh đủ mạnh, từ khả năng lạm dụng vũ khí sinh học cho đến mất kiểm soát hệ thống. (Future of Life Institute)
Ở micro-level, khảo sát nội bộ của Anthropic cho thấy kỹ sư dùng Claude cho khoảng 60% công việc và báo cáo tăng năng suất 50%, nhưng đồng thời:
Nhiều người lo mình đang “tự động hóa chính nghề của mình”.
Một số người nói thẳng là họ giấu việc dùng AI khỏi đồng nghiệp, sếp, để tránh bị đánh giá “ăn gian”.
Cộng với vụ Mixpanel rò rỉ dữ liệu OpenAI API user, và việc OpenAI phải nghĩ tới kỹ thuật “Confessions” để mô hình… tự thú lỗi, chúng ta thấy rất rõ: niềm tin bây giờ không chỉ là chuyện “model đúng hay sai”, mà là:
Người dùng cá nhân có cảm giác mình bị “quan sát” quá mức hay không.
Nhân viên có cảm giác công ty đang “đào hố” cho công việc của họ không.
Xã hội và nhà nước có cảm giác các lab đang chạy nhanh hơn khả năng kiểm soát không.
Với Việt Nam, đây là vùng tôi nghĩ chúng ta nên đi sớm nhưng đi chắc:
Hoàn thiện khung đạo đức AI, khung pháp lý để yêu cầu các hệ thống dùng AI phải minh bạch về dữ liệu, mô hình, quy trình ra quyết định.
Thiết kế chương trình đào tạo lại (reskilling) và nâng cấp kỹ năng ở cấp ngành, không đẩy rủi ro kỹ năng hoàn toàn về phía cá nhân.
Khuyến khích mô hình sử dụng AI “lộ diện” trong tổ chức, thay vì để nhân viên phải dùng lén lút và cảm thấy xấu hổ vì phụ thuộc vào công cụ.
4. Lời kết
Tuần 49 cho thấy một nghịch lý rất “thời AI”:
Năng lực mô hình tăng theo cấp số nhân, open-source chạm tầm nghiên cứu đỉnh cao, video AI tiến sát ranh giới “khó phân biệt với thật”.
Còn năng lực quản trị, bảo đảm an toàn, xây dựng niềm tin lại tăng chậm, đến mức một báo cáo quốc tế phải chấm điểm an toàn ở mức C và cảnh báo về nguy cơ “vừa chạy vừa xếp ghế”.
Với những người làm chính sách, lãnh đạo doanh nghiệp và người lao động ở Việt Nam, thông điệp tôi rút ra tuần này khá rõ:
Đừng đứng ngoài cuộc đua năng lực, nhưng cũng đừng bước vào theo kiểu “YOLO”.
Hãy coi open-source, agentic AI và hạ tầng đa cực là cơ hội chiến lược, nhưng đặt nó trong một khung đạo đức, pháp lý và nhân sự đủ chặt, đủ người thật chịu trách nhiệm.
Nếu chúng ta làm được điều đó, Việt Nam không cần có “siêu mô hình quốc gia” vẫn có thể trở thành một trong những nơi ứng dụng AI thông minh, an toàn và có chiều sâu nhất trong khu vực.
5. Tham khảo
Zhihong Shao et al., DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning, arXiv, 27/11/2025. (arXiv)
Comet, Runway Gen-4.5 Review: What it is and What is New, tổng quan hiệu năng và vị trí số 1 trên Artificial Analysis leaderboard. (CometAPI)
Future of Life Institute, AI Safety Index Report (Winter 2025), đánh giá 8 công ty AI theo 35 chỉ báo an toàn. (Future of Life Institute)
The Guardian, AI firms ‘unprepared’ for dangers of building human-level systems, report warns, tường thuật chi tiết các điểm số C/D trong AI Safety Index. (The Guardian)
OpenAI, Incident affecting Mixpanel, thông báo chính thức về sự cố bảo mật liên quan nhà cung cấp analytics. (LinkedIn)
Architecting efficient context-aware multi-agent framework for production (Google Blog)
TPUv7: Google Takes a Swing at the King (Semi Analysis)