

AI ngày càng giỏi nhưng vẫn bịa, vì sao human in the loop là bắt buộc
AI ngày càng giỏi nhưng vẫn bịa; bài viết phân tích Hallucination Leaderboard của Vectara và lý do doanh nghiệp phải có human in the loop.

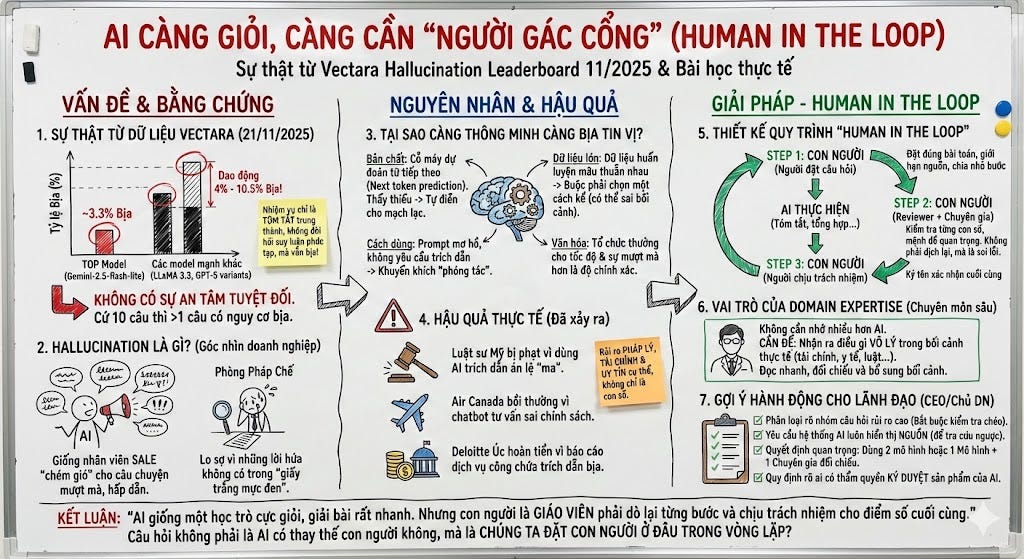
Hallucination Leaderboard của Vectara mấy năm nay đã thành một cái tên quen thuộc trong giới AI. Mỗi lần họ cập nhật, cộng đồng lại nhốn nháo soi xem model nào bịa ít hơn. Bản mới nhất, cập nhật ngày 21/11/2025, chính là cái bảng bạn đang thấy trong hình tôi đính kèm dưới bài.
Nhìn lướt qua tưởng là tin vui. Nhiều model mới, từ Google, OpenAI, Anthropic tới Mistral, DeepSeek, Qwen, IBM, Cohere, đều có tỉ lệ hallucination giảm so với các thế hệ đầu. Nhưng nếu đọc kỹ cột phần trăm, ta sẽ phải dừng lại lâu hơn.

Model tốt nhất vẫn còn hơn 3% bịa. Không ít model rất mạnh, trong đó có các biến thể GPT-5.1, dao động quanh mức 11% đến hơn 12% là bịa. Nói nôm na, cứ mười câu model trả lời, thì có hơn một câu có nguy cơ không có trong tài liệu gốc.
Và đây là kết quả trên một bộ dữ liệu khá nghiêm túc, hơn 7700 bài viết, từ khoa học, y tế, pháp lý, thể thao đến kinh doanh. Nhiệm vụ được giao cho các model không hề khó, chỉ là tóm tắt một cách trung thành tài liệu gốc, dùng duy nhất thông tin trong bài, không suy diễn, không thêm thắt. Một lần nữa khẳng định, nhiệm vụ là đơn giản và không cần “reasoning” phức tạp gì cả.
Vectara sau đó dùng một mô hình chuyên đánh giá, gọi là hallucination evaluation model, để so lại từng câu trong bản tóm tắt với tài liệu nguồn. Hễ model “kể thêm” điều gì không xuất hiện trong tài liệu, là bị tính là hallucination.
Bảng nổi tiếng này, ở phiên bản mới nhất, nhắc chúng ta một sự thật đơn giản, nhưng nhiều người đang lờ đi. Không có model nào, kể cả model hàng đầu, có thể cho chúng ta sự an tâm tuyệt đối.
Hallucination, dưới con mắt doanh nghiệp, là gì?
Nếu nói theo ngôn ngữ đời thường, hallucination giống như chuyện một nhân viên sale đọc hợp đồng, rồi hứa thêm vài điều không có trong giấy trắng mực đen. Khách hàng nghe rất thích, câu chuyện rất mượt, nhưng phòng pháp chế thì toát mồ hôi.
Trong kịch bản của Vectara, model chỉ được phép tóm tắt bài viết trước mặt, không được dùng kiến thức nội bộ, không được lôi thông tin từ nơi khác về. Thế nhưng chỉ cần nó thêm một chi tiết cho câu chuyện hấp dẫn hơn, là bản tóm tắt đã không còn trung thành với thực tế.
Điều đáng suy nghĩ là đây chính là bối cảnh rất giống cách chúng ta dùng AI hôm nay. Hầu hết hệ thống chatbot nội bộ, trợ lý số, RAG, đều yêu cầu model tóm tắt, tổng hợp, viết lại thông tin truy xuất từ tài liệu của doanh nghiệp.
Nếu ngay trong bài toán tóm tắt có nguồn rõ ràng, các model vẫn bịa từ vài đến hơn mười phần trăm, thì khi ta giao cho chúng những nhiệm vụ phức tạp hơn, rủi ro sẽ đi về đâu?
Thực tế, chúng ta đã thấy những ca rất đắt giá. Một nhóm luật sư ở Mỹ dùng AI để soạn đơn, trích dẫn hàng loạt án lệ mà sau đó tòa phát hiện là không hề tồn tại. Kết quả là họ bị phạt tiền, bị bêu tên trên báo, thậm chí đối mặt nguy cơ kỷ luật nghề nghiệp. Công cụ sinh văn thì làm đúng yêu cầu “viết cho hay”, nhưng người dùng lại quên mất trách nhiệm tối thiểu là kiểm tra từng trích dẫn.
Air Canada phải bồi thường cho một hành khách vì chatbot trên website tư vấn sai về chính sách vé giảm giá cho người thân mới mất. Hãng từng lập luận rằng chatbot là một thực thể tách biệt, nhưng tòa chỉ nói đơn giản: đó vẫn là một phần của website Air Canada, và hãng phải chịu trách nhiệm cho thông tin mà mình đưa ra.
Gần đây hơn, Deloitte tại Úc phải hoàn tiền một phần cho chính phủ vì một báo cáo dịch vụ công được soạn với hỗ trợ của AI chứa đầy trích dẫn bịa, tài liệu không tồn tại và cả câu trích dẫn từ phán quyết tòa nhưng chưa từng được nói ra. Báo cáo vẫn được in đẹp, trình bày mượt, nhưng khi các nhà nghiên cứu soi kỹ nguồn thì cả hệ thống tư vấn phải giải trình.
Những câu chuyện đó cho thấy hallucination không chỉ là con số trên leaderboard, mà đã là rủi ro pháp lý, tài chính và uy tín rất cụ thể nếu thiếu human in the loop.
Vì sao càng thông minh càng bịa tinh vi? Nhìn từ trải nghiệm thực tế khi làm việc với nhiều model khác nhau, tôi thấy có mấy lý do.
Một là, bản chất mô hình ngôn ngữ lớn là cỗ máy dự đoán từ kế tiếp, tức next token prediction dù sau này có nhiều tiến bộ như CoT, ToT bổ sung. Khi thấy thiếu dữ liệu hoặc cảm giác rằng một chi tiết nào đó “nên” có để câu chuyện mạch lạc, model rất dễ lấp chỗ trống bằng suy diễn. Mà suy diễn trôi chảy thì lại càng dễ thuyết phục người đọc.
Hai là, dữ liệu huấn luyện cực lớn vừa là sức mạnh vừa là nguồn mâu thuẫn. Cùng một khái niệm, có thể hàng nghìn tài liệu nói khác nhau. Model buộc phải chọn một cách kể. Nhưng trong một bối cảnh cụ thể, lựa chọn đó có thể không đúng.
Ba là, cách chúng ta dùng AI cũng vô tình khuyến khích hallucination. Prompt mơ hồ, không nói rõ nguồn, không yêu cầu trích dẫn, chẳng khác nào bảo một người kể chuyện giỏi cứ thoải mái phóng tác.
Bốn là, văn hóa tổ chức thường thưởng cho tốc độ và sự sáng tạo hơn là độ chính xác. Miễn là báo cáo đến đúng hạn, slide đẹp, câu chữ mượt, thì hiếm khi ai hỏi dữ liệu gốc nằm ở đâu.
Human in the loop, không phải khẩu hiệu mà là thiết kế quy trình
Nhìn vào bảng leaderboard đó, phản xạ đầu tiên của tôi không phải là tranh luận model nào hơn model nào. Thứ khiến tôi băn khoăn là quy trình, trong hệ thống của mình, con người đang đứng ở đâu.Khái niệm human in the loop nghe có vẻ học thuật, nhưng hiểu đơn giản là, con người luôn nằm trong vòng lặp. A I không được phép chạy một mình từ yêu cầu đến quyết định cuối cùng.
Trong thực tế, tôi thấy con người cần làm tối thiểu ba việc.
Một là, người đặt câu hỏi. Đặt đúng bài toán, chia nhỏ bước, giới hạn rõ nguồn được phép dùng, đã là một nửa câu chuyện.
Hai là, người soát lại, tức reviewer. Đây không phải là việc “dịch” lại câu trả lời của AI, mà là kiểm tra từng mệnh đề quan trọng, từng con số, từng kết luận, bằng con mắt và trải nghiệm của một người làm nghề.
Ba là, người chịu trách nhiệm. Cuối mỗi báo cáo, đề xuất, email gửi khách hàng, phải có một con người đủ thẩm quyền ký tên. Nếu không có chữ ký đó, tổ chức đang ngầm chấp nhận rằng mọi thứ model nói ra đều tự động trở thành sự thật.
Domain expertise, nếu không có sẽ không kiểm soát được AI
Có người hỏi tôi, nếu một model đã trả lời được ở mức PhD level, chúng ta còn cần chuyên gia làm gì nữa?Trải nghiệm của tôi khá rõ. Chúng ta vẫn cần, chỉ là vai trò thay đổi. Thay vì viết từ trang giấy trắng, chuyên gia trở thành người đọc nhanh, đối chiếu, chỉnh sửa và bổ sung bối cảnh.
Nếu bạn không có nền tảng tài chính, đọc một báo cáo phân tích do AI viết, rất khó để nhận ra một chỉ số bị tính sai, hay một giả định thị trường quá lạc quan. Với y tế, pháp lý, kỹ thuật cũng vậy, sai một chút đã đủ gây hậu quả lớn.
Domain expertise vì thế không còn là chuyện nhớ nhiều hơn AI. Nó là khả năng nhận ra điều gì hợp lý trong bối cảnh thực, điều gì nghe rất hay nhưng đem ra làm thì không thể triển khai.
Gợi ý cho lãnh đạo, thiết kế quy trình có người gác cổng
Ở góc nhìn của CEO, chủ doanh nghiệp, tôi nghĩ tối thiểu nên làm bốn việc.
Một là, phân loại rõ những nhóm câu hỏi có rủi ro cao, như pháp lý, y tế, tài chính, nhân sự. Bất cứ nội dung nào liên quan đến chúng đều bắt buộc phải được chuyên gia kiểm tra chéo trước khi gửi đi.
Hai là, yêu cầu hệ thống AI luôn hiển thị nguồn. Ưu tiên kiến trúc có truy xuất tài liệu nội bộ, để reviewer có thể bấm vào và đọc ngược lại.
Ba là, với những quyết định quan trọng, hãy cho hai mô hình khác nhau cùng trả lời, hoặc một mô hình và một chuyên gia con người cùng đánh giá. Khi hai bên lệch nhau, đó chính là vùng cần đào sâu thêm.
Bốn là, quy định rõ ai được quyền ký duyệt nội dung do AI sinh ra. Quyền đó nên đi kèm đào tạo về cách đọc, cách nghi ngờ, cách đặt câu hỏi với AI.
Kết lại, niềm tin vẫn là sản phẩm của con người
Hallucination Leaderboard của Vectara đã đi cùng cộng đồng AI vài năm, và phiên bản mới nhất này chỉ nhắc lại một điều giản dị. Chưa có mô hình nào có thể thay thế người chịu trách nhiệm cuối cùng.
AI giống một học trò cực giỏi, giải bài rất nhanh và đa số đúng, nhưng bài nào đem đi thi học sinh giỏi quốc gia, thầy cô vẫn phải dò lại từng bước. Không phải vì không tin học trò, mà vì trách nhiệm với kết quả cuối cùng.
Câu hỏi quan trọng không phải là “AI có thay con người không”. Câu hỏi là, “chúng ta đặt con người ở đâu trong vòng lặp”. Từ ngày mai, trong đội ngũ của các bạn, AI sẽ đứng ở vị trí nào, và ai sẽ là người ký tên dưới mỗi quyết định mà AI góp phần tạo ra.
Chú cho con hỏi, trong việc làm phần mềm, với 1 kỹ sư phần mềm thì họ nằm ở đâu trong quy trình làm 1 phần mềm có sử dụng AI ạ?